3. Differentiator & Sobel Filter¶
Catalog of Features¶
In this section, you will learn about the following components in Spatial:
- LineBuffer
- ShiftRegister
- LUT
- Spatial Functions and Multifile Projects
Application Overview¶
Convolution is a common algorithm in linear algebra, machine learning, statistics, and many other domains. The tutorials in this section will demonstrate how to use the building blocks that Spatial provides to do convolutions.
Specifically, we will build a basic differentiator for a time-series using sliding window averaging for an example 1D convolution. The animation below demonstrates this convolution (credit http://pages.jh.edu/~signals/convolve/index.html).
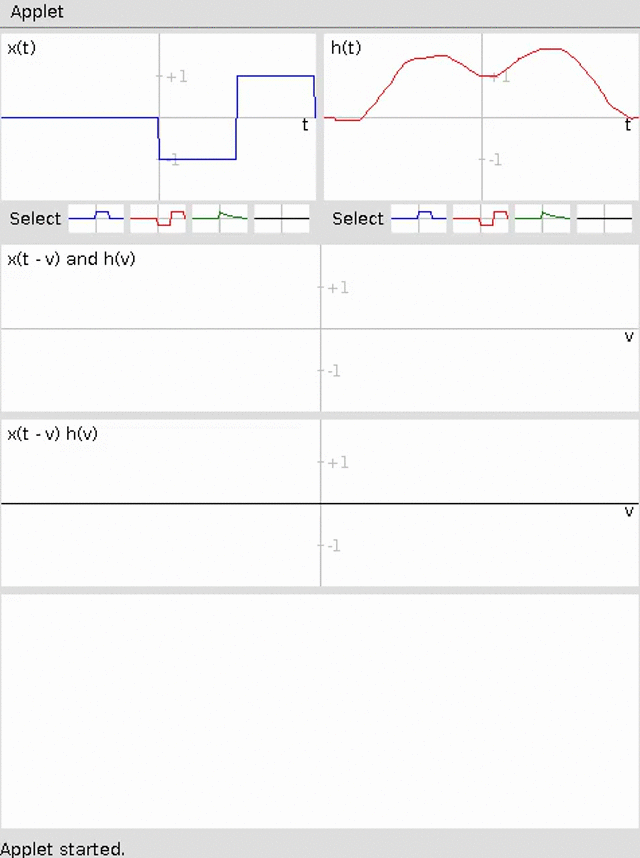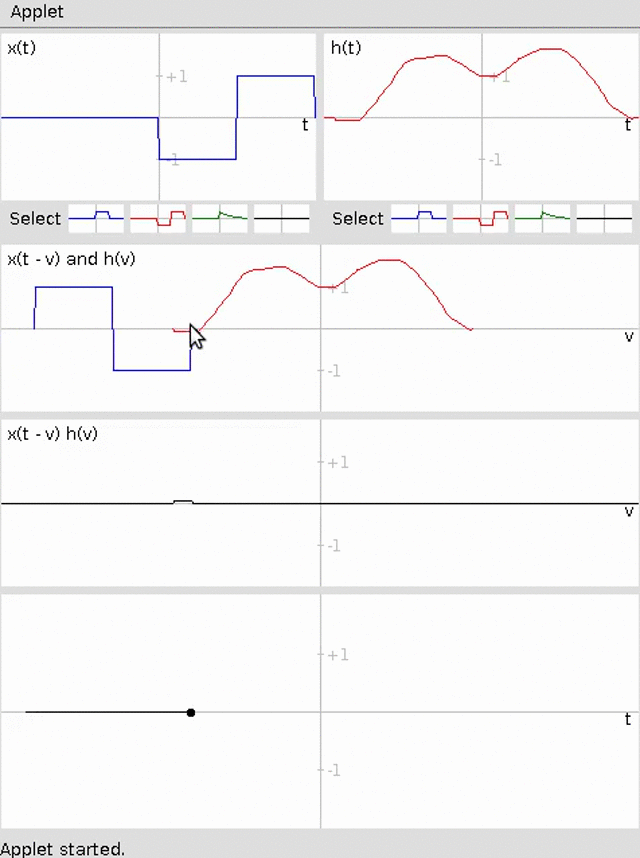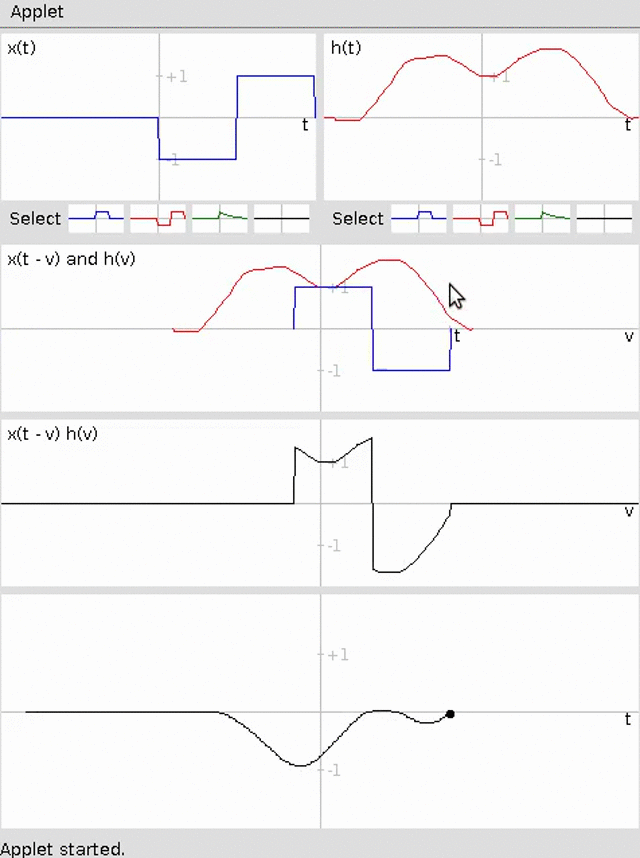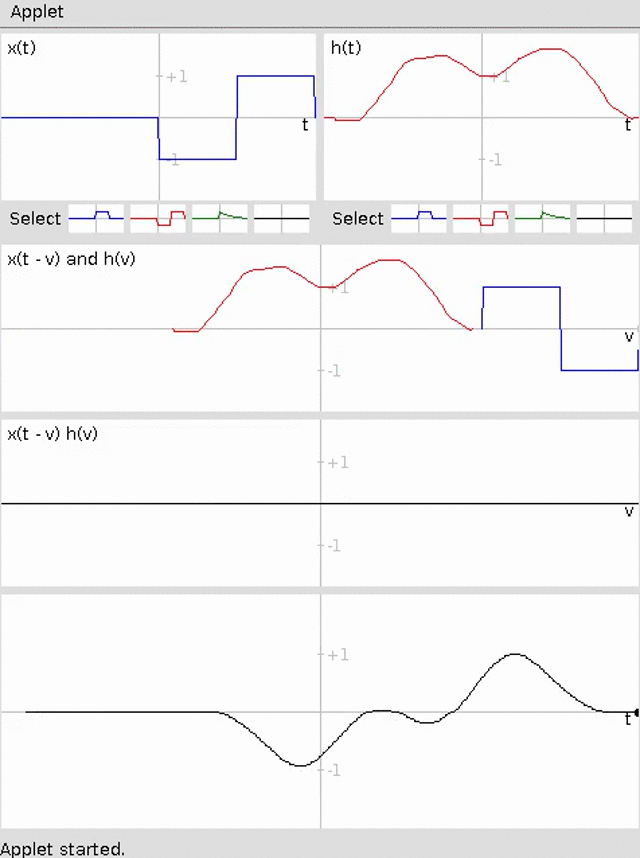
We will then build a Sobel Filter to detect edges on an image for an example of 2D convolution. A Sobel filter is the average of the convolution with the following two kernels:
KernelV:
1 2 1
0 0 0
-1 -2 -1
KernelH:
1 0 -1
2 0 -2
1 0 -1
While this section will not explore convolutions in more than 2 dimensions, it is possible to combine the Spatial primitives demonstrated in this section and previous sections to build up a higher-dimensional convolution. The animation below demonstrates the 2D convolution with the padding that we will use (credit https://github.com/vdumoulin/conv_arithmetic). Alternatively, Spatial supports 2D convolutions as matrix multiplies. See (TODO: Link to “toeplitz” API) for more details.
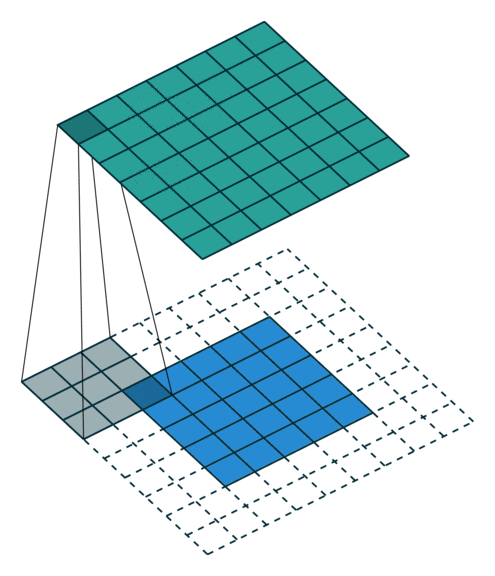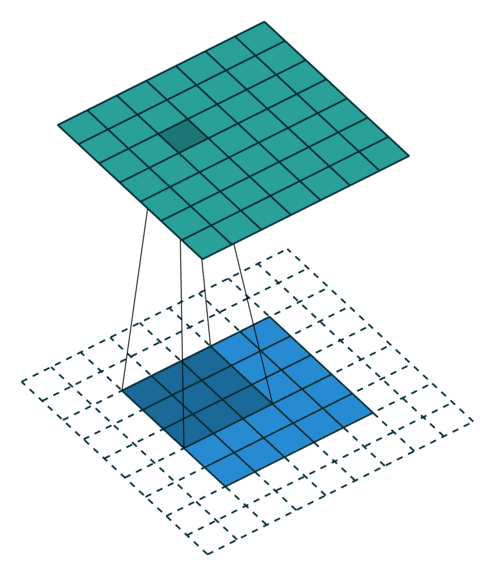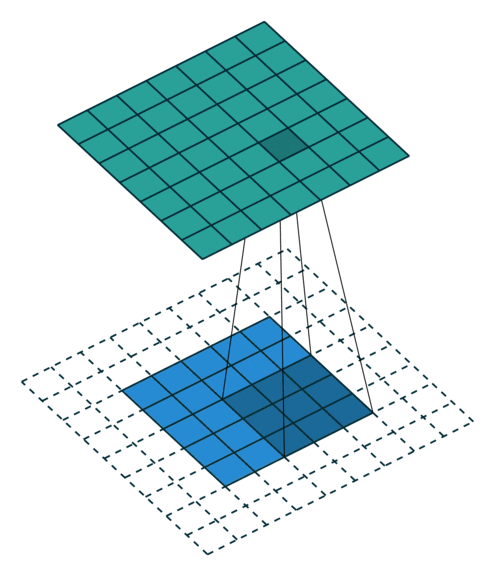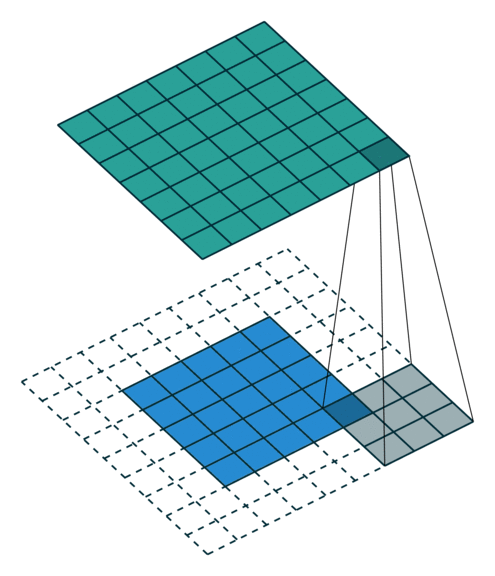
TODO: Fix right and bottom padding to match app below
Data Setup and Validation¶
Let’s start by creating the data structures above the Accel that we will set up the image and filters and compute the gold check. We will expose the rows of the images as command-line arguments.:
import spatial.dsl._
import virtualized._
object DiffAndSobel extends SpatialApp {
@virtualize
def main() {
val R = args(0).to[Int]
val C = args(1).to[Int]
val vec_len = args(2).to[Int]
val vec_tile = 64
val maxcols = 128 // Required for LineBuffer
val ROWS = ArgIn[Int]
val COLS = ArgIn[Int]
val LEN = ArgIn[Int]
setArg(ROWS,R)
setArg(COLS,C)
setArg(LEN, vec_len)
val window = 16
val x_t = Array.tabulate(vec_len){i =>
val x = i.to[T] * (4.to[T] / vec_len.to[T]).to[T] - 2
-0.18.to[T] * pow(x, 4) + 0.5.to[T] * pow(x, 2) + 0.8.to[T]
}
val h_t = Array.tabulate(16){i => if (i < window/2) 1.to[T] else -1.to[T]}
printArray(x_t, "x_t data:")
val X_1D = DRAM[T](LEN)
val H_1D = DRAM[T](window)
val Y_1D = DRAM[T](LEN)
setMem(X_1D, x_t)
setMem(H_1D, h_t)
val border = 3
val image = (0::R, 0::C){(i,j) => if (j > border && j < C-border && i > border && i < C - border) (i*16).to[T] else 0.to[T]}
printMatrix(image, "Image:")
val kernelv = Array[T](1,2,1,0,0,0,-1,-2,-1)
val kernelh = Array[T](1,0,-1,2,0,-2,1,0,-1)
val X_2D = DRAM[T](ROWS, COLS)
val Y_2D = DRAM[T](ROWS, COLS)
setMem(X_2D, image)
Accel{}
val Y_1D_result = getMem(Y_1D)
val Y_2D_result = getMatrix(Y_2D)
val Y_1D_gold = Array.tabulate(vec_len){i =>
Array.tabulate(window){j =>
val data = if (i - j < 0) 0 else x_t(i-j)
data * h_t(j)
}.reduce{_+_}
}
val Y_2D_gold = (0::R, 0::C){(i,j) =>
val h = Array.tabulate(3){ii => Array.tabulate(3){jj =>
val img = if (i-ii < 0 || j-jj < 0) 0 else image(i-ii,j-jj)
img * kernelh((2-ii)*3+(2-jj))
}}.flatten.reduce{_+_}
val v = Array.tabulate(3){ii => Array.tabulate(3){jj =>
val img = if (i-ii < 0 || j-jj < 0) 0 else image(i-ii,j-jj)
img * kernelv((2-ii)*3+(2-jj))
}}.flatten.reduce{_+_}
abs(v) + abs(h)
}
printArray(Y_1D_result, "1D Result:")
printArray(Y_1D_gold, "1D Gold:")
printMatrix(Y_2D_result, "2D Result:")
printMatrix(Y_2D_gold, "2D Gold:")
val margin = 0.25.to[T]
val cksum_1D = Y_1D_result.zip(Y_1D_gold){(a,b) => abs(a - b) < margin}.reduce{_&&_}
val cksum_2D = Y_2D_result.zip(Y_2D_gold){(a,b) => abs(a - b) < margin}.reduce{_&&_}
println("1D Pass? " + cksum_1D + ", 2D Pass? " + cksum_2D)
}
}
Note that there is a val called “maxcols.” In the 2D Convolution section, we will demonstrate how the line buffer works and it will become clear why we must constrain the maximum number of columns in our image for the app to work.
1D Convolution¶
In order to perform the 1D convolution, we need a pipeline to perform two operations. The first is to load one tile at a time, and the second is to shift data through a window and perform a dot product between this window and the filter. We must also do a one-time load of the filter kernel. The snippet below shows this code:
Accel{
val filter_data = RegFile[T](window)
filter_data load H_1D
Foreach(LEN by vec_tile){i =>
val numel = min(vec_tile.to[Int], LEN-i)
val x_tile = SRAM[T](vec_tile)
val y_tile = SRAM[T](vec_tile)
x_tile load X_1D(i::i+numel)
val sr1D = RegFile[T](1,window)
Foreach(numel by 1){j =>
sr1D(0,*) <<= x_tile(j) // Shift new point into sr1D
y_tile(j) = Reduce(Reg[T])(window by 1){k =>
val data = mux(i + j - k < 0, 0.to[T], sr1D(0,k)) // Handle edge case
data * filter_data(k)
}{_+_}
}
Y_1D(i::i+numel) store y_tile
}
}
The app above uses familiar concepts described in previous parts of this tutorial, except for
the RegFiles. The first RegFile, filter_data, is created to hold the filter data. It is
equally valid to use an SRAM for this structure, but it is generally more efficient for small
memories to use RegFiles, as this reduces the number of wasted addresses in a physical BRAM on-chip.
The second RegFile, sr1D, is used as a shift register. We use the <<= operator to indicate that
we want to shift into it from the entry address (i.e.- address 0), and move all the existing data backwards by
one address. Later, we will see how to specify strides for shift registers, as well as shift into an entry
plane of a multidimensional shift register.
While this app uses tiles to perform convolution, it is possible to use the shift register in the same way to do convolution on streaming data by directly enqueueing to the shift register. Also, it may not seem completely intuitive that we use the shift register at all, since we can just index into the x_tile directly. However, if you want to parallelize the reduction, the shift register comes fully banked since it is composed of registers. Parallel accesses to the SRAM directly, with a sliding window, will result in lots of SRAM duplication and inefficiency.
Finally, there is a mux inside the Reduce map function. This mux is to check if the data in a particular
address of the shift register corresponds to data with a “negative” address in the X_1D data structure.
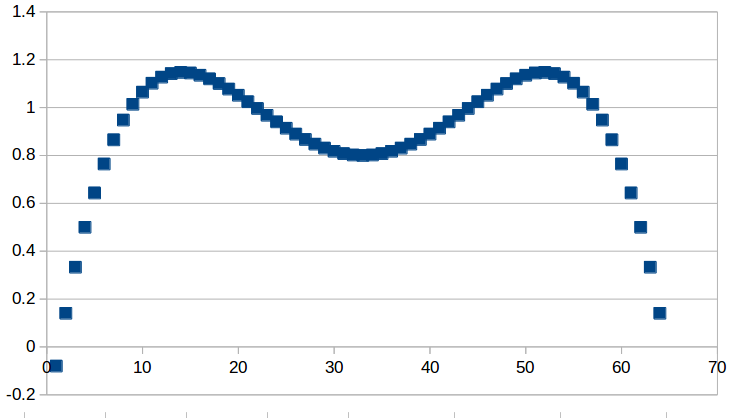
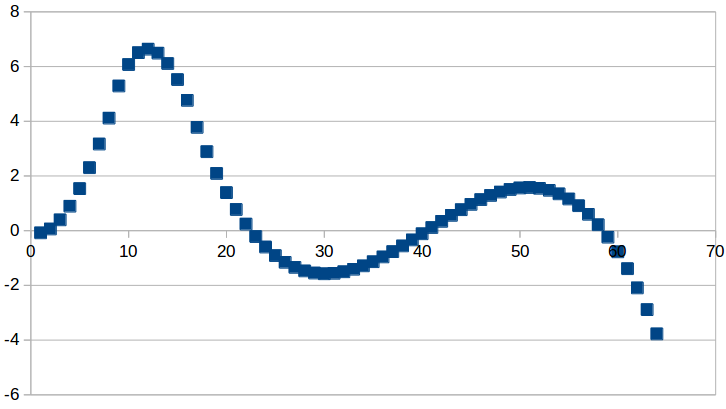
If you plot the resulting data in a spreadsheet, you should get something that looks like this. We can use these plots as a sanity check for our differentiator kernel.
Input:
Derivative:
2D Convolution¶
Now we will focus on the Sobel filter that will perform a 2D convolution. First, we will introduce a LineBuffer memory structure. A LineBuffer is a special case on an N-buffered 1D SRAM exposed to the user. It allows one or more rows of DRAM to be buffered into on-chip memory while previous rows can be accessed in a logically-rotating way. A LineBuffer is generally coupled with a shift register, and the animation below shows the specific usage of this pair in this tutorial.
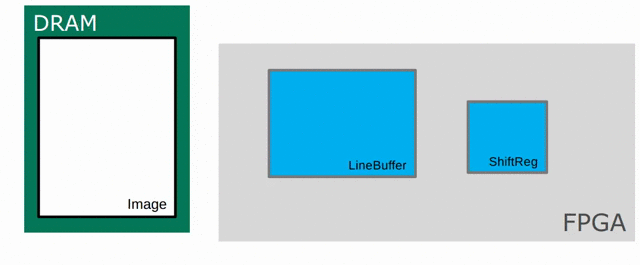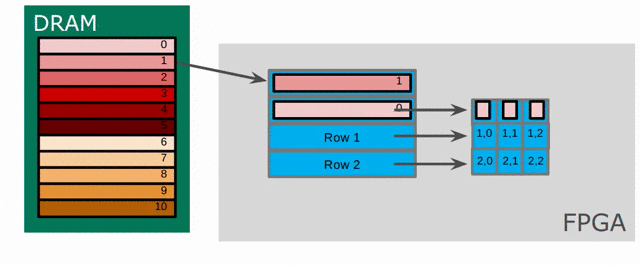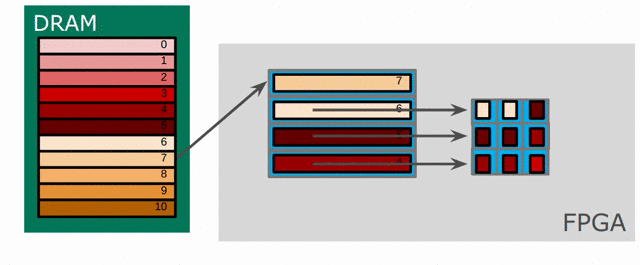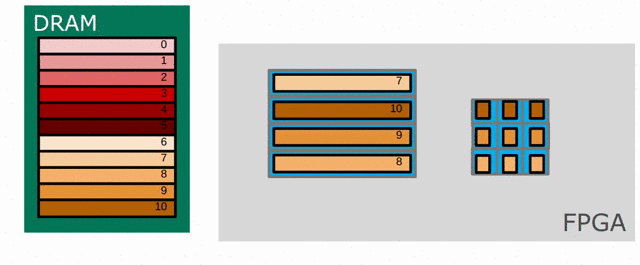
Note that in the last frame, the “buffer” row of the line buffer contains row 7 of the image. This is because this line buffer is physically implemented with four SRAMs and uses access redirection to create the logical behavior shown in the animation. After the last row is loaded and we drain the last frame, the buffers inside the line buffer will rotate but no new line will fill the buffer SRAM, leaving behind the data from row 7 even though it will not get used in this particular case. The Spatial compiler will also determine how to bank and duplicate the SRAMs that compose the line buffer automatically, should you choose to have a strided convolution.
It is also possible now to see why we must set a hard cap on the number of columns in the image if we are to use the line buffer - shift register combination. The logic that handles the rotation of the line buffer rows is tied to the controller hierarchy that manages the writes and reads about the line buffer. If we were to try to tile this operation along the columns, then our line buffer would load one tile of the row into the buffer, while row 0 of the line buffer would contain the previous part of that row. This splitting of a single line is semantically incorrect for convolution.
For this 2D convolution, we also introduce the lookup table (LUT). This is a read-only memory whose values are known at compile time. It is implemented using registers and muxes to index into it.
The snippet below shows how to generate an accel that performs the operations shown above:
Accel {
val lb = LineBuffer[T](3, maxcols)
val sr = RegFile[T](3, 3)
val kernelH = LUT[T](3,3)(1.to[T], 2.to[T], 1.to[T],
0.to[T], 0.to[T], 0.to[T],
-1.to[T],-2.to[T],-1.to[T])
val kernelV = LUT[T](3,3)(1.to[T], 0.to[T], -1.to[T],
2.to[T], 0.to[T], -2.to[T],
1.to[T], 0.to[T], -1.to[T])
val lineout = SRAM[T](maxcols)
Foreach(ROWS by 1){row =>
lb load X_2D(row, 0::COLS)
Foreach(COLS by 1){j =>
Foreach(3 by 1 par 3){i => sr(i,*) <<= lb(i,j)}
val accumH = Reduce(Reg[T](0.to[T]))(3 by 1, 3 by 1){(ii,jj) =>
val img = if (row - 2 + ii.to[Int] < 0 || j.to[Int] - 2 + jj.to[Int] < 0) 0.to[T] else sr(ii, 2 - jj)
img * kernelH(ii,jj)
}{_+_}
val accumV = Reduce(Reg[T](0.to[T]))(3 by 1, 3 by 1){(ii,jj) =>
val img = if (row - 2 + ii.to[Int] < 0 || j.to[Int] - 2 + jj.to[Int] < 0) 0.to[T] else sr(ii, 2 - jj)
img * kernelV(ii,jj)
}{_+_}
lineout(j) = abs(accumV.value) + abs(accumH.value)
}
Y_2D(row, 0::COLS) store lineout
}
}
It is possible to improve the performance of this algorithm using parallelization. However, we leave this as an exercise to the user or direct the user to some example apps written in the spatial-apps repository. While parallelizing every loop will speed up this algorithm, some loops will give incorrect results if parallelized while others will maintain the correct result if extra code is added to handle the edge cases appropriately
Spatial Functions and Multifile¶
Sometimes complicated apps can get very cluttered inside the Accel block so you will want to break your app into multiple functions, possibly across multiple files. Now we will aim to create the following Accel block, where the method calls are defined in a separate file:
Accel{
Conv1D(Y_1D, X_1D, H_1D, window, vec_tile) // Output DRAM, Input Data, Kernel
Sobel2D(Y_2D, X_2D, maxcols) // Output DRAM, Input Image
}
We can write the functions used above as follows:
@virtualize
def Conv1D[T:Type:Num](output: DRAM1[T],
input: DRAM1[T],
filter: DRAM1[T],
window: scala.Int, vec_tile: scala.Int): Unit = {
val filter_data = RegFile[T](window)
filter_data load filter
Foreach(input.size by vec_tile){i =>
val numel = min(vec_tile.to[Int], input.size-i)
val x_tile = SRAM[T](vec_tile)
val y_tile = SRAM[T](vec_tile)
x_tile load input(i::i+numel)
val sr1D = RegFile[T](1,window)
Foreach(numel by 1){j =>
sr1D(0,*) <<= x_tile(j) // Shift new point into sr1D
y_tile(j) = Reduce(Reg[T])(window by 1){k =>
val data = mux(i + j - k < 0, 0.to[T], sr1D(0,k)) // Handle edge case
data * filter_data(k)
}{_+_}
}
output(i::i+numel) store y_tile
}
}
@virtualize
def Sobel2D[T:Type:Num](output: DRAM2[T],
input: DRAM2[T], maxcols: scala.Int): Unit = {
val lb = LineBuffer[T](3, maxcols)
val sr = RegFile[T](3, 3)
val kernelH = LUT[T](3,3)(1.to[T], 2.to[T], 1.to[T],
0.to[T], 0.to[T], 0.to[T],
-1.to[T],-2.to[T],-1.to[T])
val kernelV = LUT[T](3,3)(1.to[T], 0.to[T], -1.to[T],
2.to[T], 0.to[T], -2.to[T],
1.to[T], 0.to[T], -1.to[T])
val lineout = SRAM[T](maxcols)
Foreach(input.rows by 1){row =>
lb load input(row, 0::input.cols)
Foreach(input.cols by 1){j =>
Foreach(3 by 1 par 3){i => sr(i,*) <<= lb(i,j)}
val accumH = Reduce(Reg[T](0.to[T]))(3 by 1, 3 by 1){(ii,jj) =>
val img = if (row - 2 + ii.to[Int] < 0 || j.to[Int] - 2 + jj.to[Int] < 0) 0.to[T] else sr(ii, 2 - jj)
img * kernelH(ii,jj)
}{_+_}
val accumV = Reduce(Reg[T](0.to[T]))(3 by 1, 3 by 1){(ii,jj) =>
val img = if (row - 2 + ii.to[Int] < 0 || j.to[Int] - 2 + jj.to[Int] < 0) 0.to[T] else sr(ii, 2 - jj)
img * kernelV(ii,jj)
}{_+_}
lineout(j) = abs(accumV.value) + abs(accumH.value)
}
output(row, 0::input.cols) store lineout
}
}
Notice that instead of using the input arguments, ROWS, COLS, and LEN, we can use
properties defined on the DRAMs directly.
You can place these functions anywhere inside of your DiffAndSobel object. If you want to place them inside of a separate file entirely, then you simply need to make the trait that contains the method definitions extend SpatialApp, and then have the next file create an object that extends the first trait:
import virtualized._
import spatial.dsl._
object AccelFile extends FunctionsFile {
@virtualize
def main() {
Accel {
FunctionsFile.fcn_call()
}
}
--------------------------------
import virtualized._
import spatial.dsl._
trait FunctionsFile extends SpatialApp{
@virtualize
def fcn_call() {/* do things */}
}
Final Code¶
Below is the final code for a single-file, functionized version of the two convolutions discussed in this tutorial. See the HelloWorld page for a refresher on how to compile and test.:
import spatial.dsl._
import virtualized._
object DiffAndSobel extends SpatialApp {
@virtualize
def Conv1D[T:Type:Num](output: DRAM1[T],
input: DRAM1[T],
filter: DRAM1[T],
window: scala.Int, vec_tile: scala.Int): Unit = {
val filter_data = RegFile[T](window)
filter_data load filter
Foreach(input.size by vec_tile){i =>
val numel = min(vec_tile.to[Int], input.size-i)
val x_tile = SRAM[T](vec_tile)
val y_tile = SRAM[T](vec_tile)
x_tile load input(i::i+numel)
val sr1D = RegFile[T](1,window)
Foreach(numel by 1){j =>
sr1D(0,*) <<= x_tile(j) // Shift new point into sr1D
y_tile(j) = Reduce(Reg[T])(window by 1){k =>
val data = mux(i + j - k < 0, 0.to[T], sr1D(0,k)) // Handle edge case
data * filter_data(k)
}{_+_}
}
output(i::i+numel) store y_tile
}
}
@virtualize
def Sobel2D[T:Type:Num](output: DRAM2[T],
input: DRAM2[T], maxcols: scala.Int): Unit = {
val lb = LineBuffer[T](3, maxcols)
val sr = RegFile[T](3, 3)
val kernelH = LUT[T](3,3)(1.to[T], 2.to[T], 1.to[T],
0.to[T], 0.to[T], 0.to[T],
-1.to[T],-2.to[T],-1.to[T])
val kernelV = LUT[T](3,3)(1.to[T], 0.to[T], -1.to[T],
2.to[T], 0.to[T], -2.to[T],
1.to[T], 0.to[T], -1.to[T])
val lineout = SRAM[T](maxcols)
Foreach(input.rows by 1){row =>
lb load input(row, 0::input.cols)
Foreach(input.cols by 1){j =>
Foreach(3 by 1 par 3){i => sr(i,*) <<= lb(i,j)}
val accumH = Reduce(Reg[T](0.to[T]))(3 by 1, 3 by 1){(ii,jj) =>
val img = if (row - 2 + ii.to[Int] < 0 || j.to[Int] - 2 + jj.to[Int] < 0) 0.to[T] else sr(ii, 2 - jj)
img * kernelH(ii,jj)
}{_+_}
val accumV = Reduce(Reg[T](0.to[T]))(3 by 1, 3 by 1){(ii,jj) =>
val img = if (row - 2 + ii.to[Int] < 0 || j.to[Int] - 2 + jj.to[Int] < 0) 0.to[T] else sr(ii, 2 - jj)
img * kernelV(ii,jj)
}{_+_}
lineout(j) = abs(accumV.value) + abs(accumH.value)
}
output(row, 0::input.cols) store lineout
}
}
@virtualize
def main() {
type T = FixPt[TRUE,_16,_16]
val R = args(0).to[Int]
val C = args(1).to[Int]
val vec_len = args(2).to[Int]
val vec_tile = 64
val maxcols = 128 // Required for LineBuffer
val ROWS = ArgIn[Int]
val COLS = ArgIn[Int]
val LEN = ArgIn[Int]
setArg(ROWS,R)
setArg(COLS,C)
setArg(LEN, vec_len)
val window = 16
val x_t = Array.tabulate(vec_len){i =>
val x = i.to[T] * (4.to[T] / vec_len.to[T]).to[T] - 2
println(" x " + x)
-0.18.to[T] * pow(x, 4) + 0.5.to[T] * pow(x, 2) + 0.8.to[T]
}
val h_t = Array.tabulate(16){i => if (i < window/2) 1.to[T] else -1.to[T]}
printArray(x_t, "x_t data:")
val X_1D = DRAM[T](LEN)
val H_1D = DRAM[T](window)
val Y_1D = DRAM[T](LEN)
setMem(X_1D, x_t)
setMem(H_1D, h_t)
val border = 3
val image = (0::R, 0::C){(i,j) => if (j > border && j < C-border && i > border && i < C - border) (i*16).to[T] else 0.to[T]}
printMatrix(image, "image: ")
val kernelv = Array[T](1,2,1,0,0,0,-1,-2,-1)
val kernelh = Array[T](1,0,-1,2,0,-2,1,0,-1)
val X_2D = DRAM[T](ROWS, COLS)
val Y_2D = DRAM[T](ROWS, COLS)
setMem(X_2D, image)
Accel{
Conv1D(Y_1D, X_1D, H_1D)
Sobel2D(Y_2D, X_2D)
}
val Y_1D_result = getMem(Y_1D)
val Y_2D_result = getMatrix(Y_2D)
val Y_1D_gold = Array.tabulate(vec_len){i =>
Array.tabulate(window){j =>
val data = if (i - j < 0) 0 else x_t(i-j)
data * h_t(j)
}.reduce{_+_}
}
val Y_2D_gold = (0::R, 0::C){(i,j) =>
val h = Array.tabulate(3){ii => Array.tabulate(3){jj =>
val img = if (i-ii < 0 || j-jj < 0) 0 else image(i-ii,j-jj)
img * kernelh((2-ii)*3+(2-jj))
}}.flatten.reduce{_+_}
val v = Array.tabulate(3){ii => Array.tabulate(3){jj =>
val img = if (i-ii < 0 || j-jj < 0) 0 else image(i-ii,j-jj)
img * kernelv((2-ii)*3+(2-jj))
}}.flatten.reduce{_+_}
abs(v) + abs(h)
}
printArray(Y_1D_result, "1D Result:")
printArray(Y_1D_gold, "1D Gold:")
printMatrix(Y_2D_result, "2D Result:")
printMatrix(Y_2D_gold, "2D Gold:")
val margin = 0.25.to[T]
val cksum_1D = Y_1D_result.zip(Y_1D_gold){(a,b) => abs(a - b) < margin}.reduce{_&&_}
val cksum_2D = Y_2D_result.zip(Y_2D_gold){(a,b) => abs(a - b) < margin}.reduce{_&&_}
println("1D Pass? " + cksum_1D + ", 2D Pass? " + cksum_2D)
}
}